Infinite Quorum
An experiment in what hundreds of cheap, fast intelligences can tell you about a piece of persuasive writing.
The Less Obvious Uses
Most of what I use AI for is the obvious thing: one very capable agent helping me write code, draft a document, or run down research I couldn't get to on my own. That's the use everyone pictures, and it's real.
Something quieter happened alongside the capability race: intelligence got cheap. Absurdly cheap. In one of my early benchmarks for this project, a full structured read of a legal brief by twelve separate AI readers cost about six tenths of a cent. At those prices a second category of tool opens up — built not around one brilliant assistant but around a crowd. Populations that read. Audiences that react. Simulations you can afford to run on a whim. Things nobody could build before, because nobody could hire five hundred readers for a quarter.
MiroFish
In early March 2026, a project called MiroFish started showing up everywhere I looked. It's open source, built by Guo Hangjiang, a college senior in Beijing: feed it real-world seed material — a policy draft, a news story, a company's financials — and it constructs a parallel digital world populated by thousands of AI personas with their own personalities and memories, then lets the simulated society react so you can watch what might happen before it does. It went to #1 on GitHub's global trending list, collected tens of thousands of stars, and within about a day of the demo video its author had a four-million-dollar seed check.
I had been circling ideas in this family for a while without building any of them. MiroFish settled the question of whether the category was interesting to anyone but me, and it embarrassed me into starting. Twelve days after it topped the charts, I had a working prototype of my own.
The Idea
What I started playing with became Infinite Quorum. Where MiroFish simulates a society at large, I wanted something narrower: take one piece of writing that has to persuade — a brief, an opening statement, a memo — and put it in front of a very large number of simulated readers, to get an early sense of how people out in the world might actually receive it.
The use case I cared about was legal. Empaneling a real mock jury costs tens of thousands of dollars and takes weeks, so most briefs and arguments go out the door having been read by their authors and maybe two colleagues. The rest of the testing happens at trial, when the test is real and the stakes are everything.
Jury simulation was the anchor, but the idea is broader than juries. Judges are not juries — they read differently, and they've seen every trick — but they are also real people, and real people have reactions to a fact or an argument that a lawyer who has lived inside a case for two years stops being able to predict. Any audience you can describe, you can approximate: a judge, opposing counsel, a general reader, a skeptical client. So I started building an artificial focus group.
The natural abbreviation is IQ. "We ran it through IQ." "What did IQ say about the closing?"
The First Build
Version 1 came together fast — the core pipeline in one long session on March 19, a full web interface three days later, deployed to iq.brantkuehn.com by March 24. The system works like this:
Population Generation
A configurable population of 10–500 agents built from realistic demographic and psychographic distributions. Each agent gets a full persona: age, region, education, occupation, political lean, life events, reading style, cognitive biases. Seeded RNG throughout: same seed, same population, which is what makes A/B tests reproducible.
Multi-Model Diversity
Agents are spread across nine different LLMs from four providers, round-robin, free tier through premium. Different models react differently to the same text, which crudely mimics real human variation in reading and reasoning.
Survey Pass
Every agent reads the document — paragraph-numbered so they can cite specific sections — and returns a 23-field structured survey: numeric ratings, verdict leans, free-text reactions, and references to the paragraphs that most and least persuaded them. Async and parallel, with per-run cost tracking.
Focus Group Deliberation
Subsets of the population get assembled into multi-turn moderated focus groups. Engagement tracking, post-discussion surveys, and a record of which agents persuaded which other agents. Deliberation often moves the median view in ways the survey alone doesn't show.
Report Compilation
Section-attention heatmaps showing which paragraphs drew fire, demographic breakdowns, before-and-after opinion shifts, and A/B comparisons when two documents run through the same population.
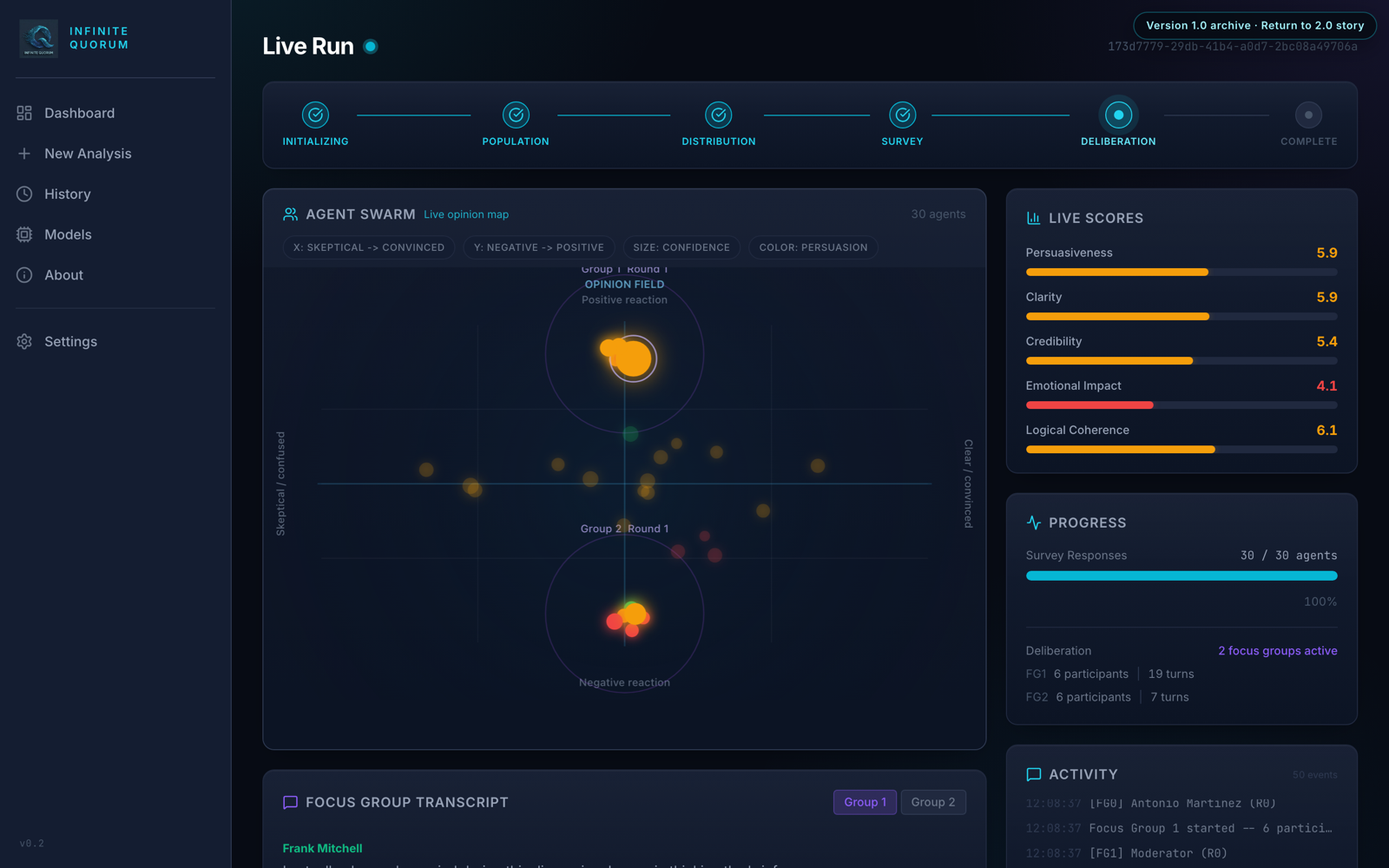
The first real run produced a finding I could act on the same afternoon. Testing a fraudulent-transfer brief, the attention heatmap showed the narrative sections — the story of the transfers, the badges of fraud — scoring highest with the panel, while the statutory citation block at the end was consistently flagged as confusing and least compelling. Whatever you think of simulated readers, that is exactly the shape of feedback a writer wants.
What It's Useful For
Brief Optimization
Run a brief against a representative population. See which sections lost which readers. Rewrite, run again. The cycle takes minutes instead of weeks.
A/B Argument Testing
Run two versions of the same brief — or two opposing briefs — through the same seeded population. Read the difference, not the absolute numbers.
Mock Jury Deliberation
Assemble a virtual panel and let it deliberate. Watch where consensus forms, which arguments move holdouts, and how opinions shift between first read and final word.
Opening Statement Variants
Test an analytical opening against a narrative one through the same population. Which framing moves which segments, and where the deliberation pushes them.
What the Prototype Taught Me
I want to be straightforward about what this is and isn't. Agent panels are not a replacement for live focus groups. The agents read fast and never get tired, but they also don't get bored, distracted, or hungry, and their priors come from training data rather than lived experience. What IQ is good at is rapid, cheap iteration: testing the directional effect of changes, not predicting verdicts.
The real comparison is not IQ versus a real focus group. It's IQ versus the zero focus groups most matters actually get. Tested rough is better than untested polished.
The deeper lesson from months of running it: scale alone is not the answer. Five hundred simulated jurors are worth little if you can't say whether the score would hold on a re-run, so reproducibility, visible uncertainty, and knowing when not to trust a number turned out to matter more than the size of the swarm. That conclusion drove everything in Version 2.
The hardest technical problem is making a simulated juror sound like a person rather than a model playing one. Focus-group agents would sometimes leak their planning voice — "We need to draft a response that..." — instead of just talking. I ended up building an offline evaluator that scores saved runs for planning leakage, generic hedging, document anchoring, and stereotype risk, so persona quality can be measured instead of eyeballed.
One feature taught me an ethics lesson by existing. An early build offered voir dire strike-and-seat suggestions ranked by demographic lean — technically easy, and exactly the wrong thing to automate. Version 2 drops it in favor of surfacing case-relevant attitudes and neutral questions, and leaves judgment where it belongs, with the lawyer.
And the honest wart list: some cheap models truncate JSON at lower token limits than they advertise; free-tier models occasionally return empty surveys; upstream rate limits come and go; and one specific agent named Kevin Rodriguez seems cursed and fails in every focus-group run for reasons I have not yet diagnosed.
Version 2: The Argument Wind Tunnel
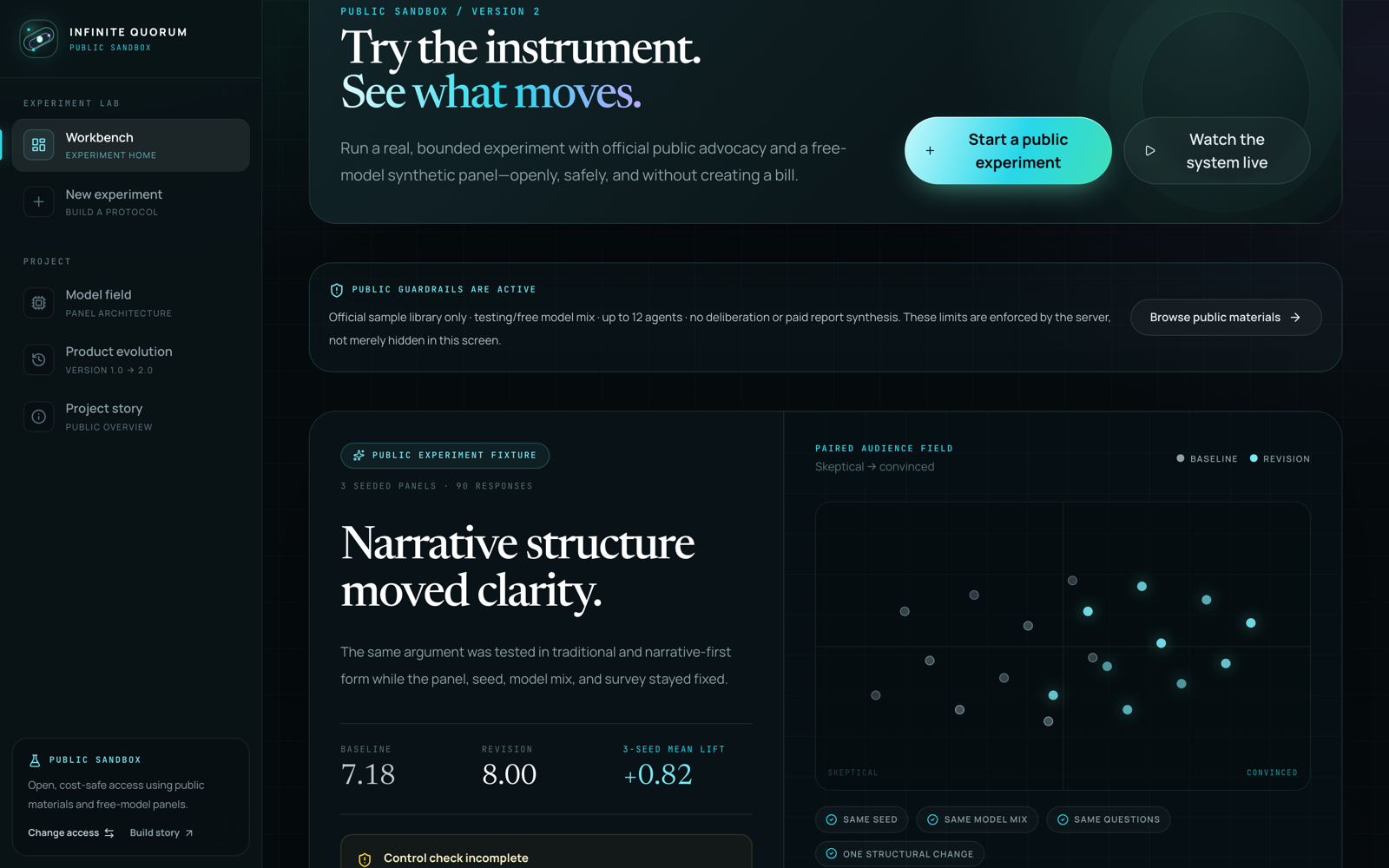
Version 1 answered "can hundreds of agents read a brief and say something useful?" The question that actually matters is "when the score moves, should you believe it?" So the current build is organized around matched-panel experiments: freeze the panel — same seed, same personas, same model mix, same questions — change exactly one thing about the argument, and measure what moves.
Every experiment starts with a pre-committed protocol: the hypothesis, the one variable being changed, and the success threshold, all declared before the run so the result can't be quietly reinterpreted afterward. Controls come standard — run the versions in reverse order to catch order effects, run a placebo pass where nothing changed to see the noise floor, repeat across seeds to check stability.
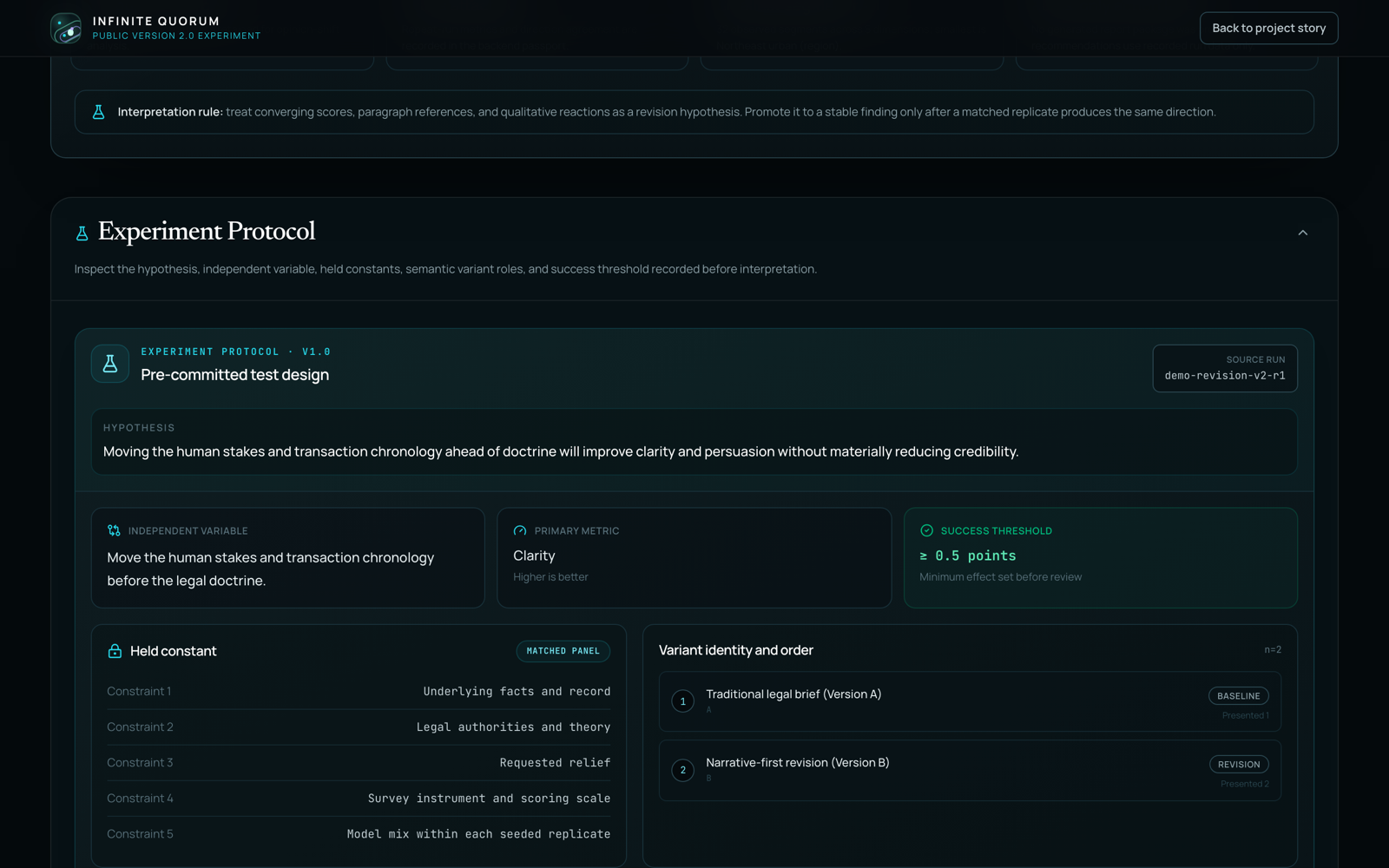
The report leads with an Action Board instead of a wall of charts: what to preserve, what to change now, what to test next, and — just as important — what not to overread. An honesty meter flags over-clean consensus and thin subgroups. And when the run is done you can interrogate the panel: pose a hypothetical to a juror by name ("how does your verdict change if the financial records are struck?") and each one answers in three layers — prior belief, reaction, whether their verdict actually moves.
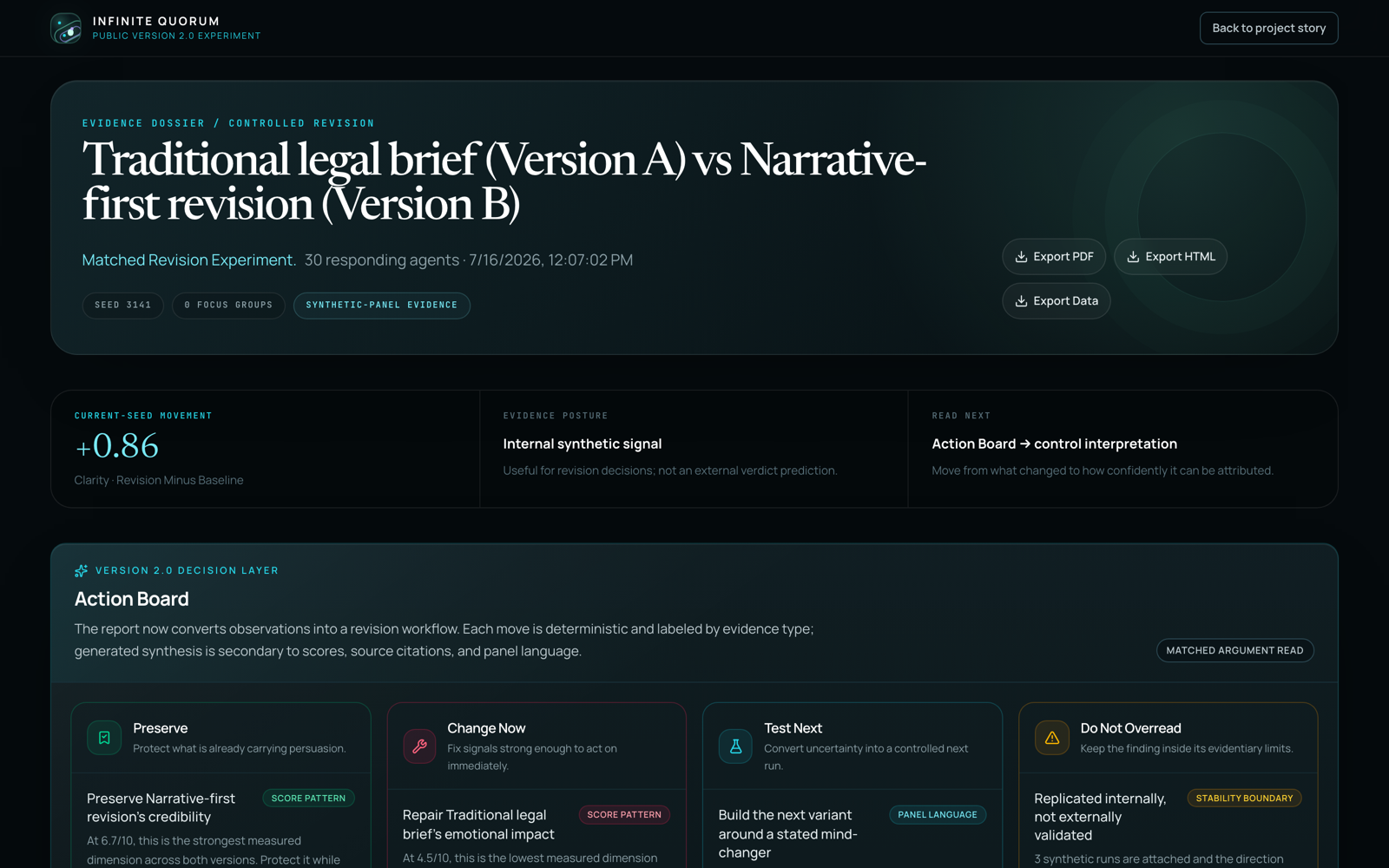
All of it is public. The showcase at iq.brantkuehn.com has an open sandbox — free models only, public sample materials, caps enforced server-side — so anyone can run a real bounded experiment without an account and without creating a bill. And Version 1 is preserved there as a frozen, runnable archive, because the distance between the two builds is the most honest exhibit on the site.
The Timeline
MiroFish tops GitHub's global trending list. I stop circling and start building.
The full Version 1 pipeline — population, survey, focus groups, reports — built in one long session. First live runs the same day.
Complete web interface: analysis wizard, live agent-swarm visualization, interactive reports.
Deployed to iq.brantkuehn.com. A reliability benchmark that day: 12 agents, 12 valid structured surveys, total cost $0.0063.
Persona-quality experiments and the offline evaluator: measuring planning leakage, hedging, and stereotype risk in saved runs.
Juror interrogation, opinion-flow visuals, the honesty meter, and a full visual redesign.
Version 2: matched-panel experiments with pre-committed protocols, the public sandbox, and Version 1 preserved as a runnable archive.
What's Next
The list of things I want to play with is longer than the list of things built, which feels right for a project like this. A validation gallery, running the system against famous public matters where the outcome is known — as context for calibration, not proof of prediction. Deep personas built from interview or deposition text instead of demographic distributions. The Holdout: an adversarial juror seeded into deliberation to see whether the group can be moved by a bad-faith argument. What-if editing, where the report suggests a revision and immediately tests it on the same panel. And eventually the honest experiment — anchoring a synthetic panel against a real human one to find out exactly how far the toy is from the instrument.
Sibling project to BenchLab: IQ tests advocacy against juries and general audiences; BenchLab tests advocacy against judges.