BenchLab
A flight simulator for litigators. Upload your matter, argue aloud against a simulated judge, and walk away with the transcript, the scorecard, and a citation trace for every critique.
The Premise
Most oral argument prep is moot court with a borrowed colleague. It works, but it's expensive in time, hard to schedule, and impossible to repeat. The really high-stakes practice — appellate argument, motion-in-limine arguments before a tough trial judge, dispositive motion hearings — gets one or two passes if you're lucky, and the feedback you get is whatever your moot judge happened to think of in the moment.
BenchLab is built around a different premise: that a litigator should be able to step into a focused, voice-first practice room as often as they want, argue against a skeptical judge calibrated to their case, and leave with structured feedback grounded in their own materials.
A skeptical judge on demand, and a scorecard that shows its work.
The Phase A Loop
Phase A is intentionally narrow: a single-judge demo that proves the loop. One matter at a time, one judge or judge archetype, one advocate. The user uploads briefs, motions, key authorities, prior hearing transcripts, and prep notes. The system parses and chunks the materials, builds an inspectable matter packet — issues, facts, posture, authorities, weak points, likely questions — and the user reviews it before the session starts.
Then the live session: bidirectional, low-latency voice. The judge interrupts. Asks pointed questions. Pushes on the weak points the matter packet flagged. The system retrieves relevant chunks of the briefs and authorities in real time, so the judge's questions are grounded in the actual record rather than confabulated.
After the session, the output: a full transcript with speaker labels, a timeline of interruptions and topic shifts, a scorecard rating answer structure, responsiveness, command of the record, concession discipline, issue framing, and remedy clarity. Every critique on the scorecard links back to the specific transcript turn, the retrieved chunk, and the judge-card behavior rule that produced it. Legal users will forgive an unpolished citation trail; they will not forgive a confident critique with no provenance.
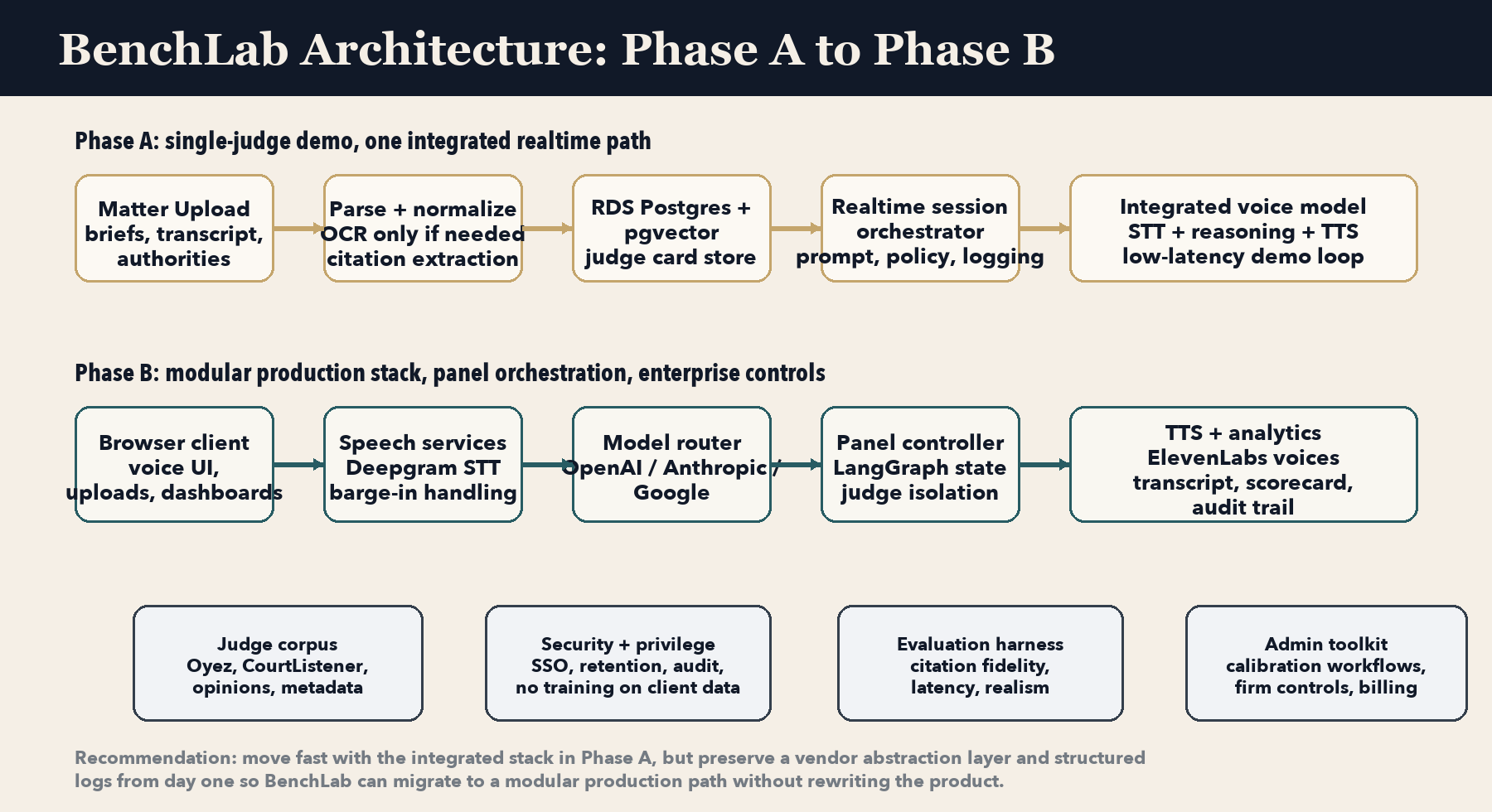
Phase A integrated path, Phase B modular stack
What's In, What's Out
Phase A — In Scope
- One matter, one judge or archetype
- Document upload and ingestion
- Inspectable matter packet
- Realtime voice session, interruptible
- Transcript with speaker labels
- Scorecard with rubric and trace
- Retrieval/citation trace per critique
- Internal calibration controls
Phase A — Out of Scope
- Multi-judge panels
- Cloned voices or photoreal avatars
- Outcome prediction
- Firm-wide dashboards
- Mobile apps
- Procurement-grade tenant admin
- Named-judge calibration depth
- Enterprise SSO/SCIM, audit, regional deployment
Scope discipline is the thing most likely to make or break the build. Panels, avatars, voice cloning, and predictive analytics could each absorb the whole project before the basic loop works. Phase A is the loop; Phase B is the platform.
The Real Risks
Five risks I'm tracking, in roughly the order they bite:
Latency
If the turn-taking feels slow, the demo fails emotionally even when the reasoning is good. Voice latency is the first thing that has to be right.
Grounding
Untraceable critiques destroy trust faster than any single bad answer. Every scorecard line gets a citation back to the matter or the transcript.
Privilege
Lawyers will not upload sensitive materials without a clear data-handling posture. Retention, isolation, and deletion need to be answered before anything moves.
Likeness
Named-judge mode is more impressive and carries real overclaim and rights risk. The default for Phase A is a fictionalized archetype, with named-judge gated on legal review.
Scope Creep
Panel mode, avatars, and voice cloning are the obvious ways to wreck the build. Phase A is locked to one judge, one matter, one advocate.
Evaluation
Without structured feedback from real test users, "realistic" becomes subjective. A feedback rubric and design-partner cohort are part of Phase A, not a Phase B luxury.
Where It Stands
BenchLab is currently a research workspace, not yet an application. What exists today is the strategic and technical foundation: judge-modeling research paper, data-moat memo, architecture memos from four different model families used as cross-checks, an investor whitepaper, a detailed budget and roadmap, the Phase A implementation brief, and the artifact inventory tying it together.
The next high-value move is the narrow Phase A prototype itself: a thin app stack (Next.js, FastAPI, Postgres with pgvector, a realtime voice adapter) built around the loop above. The build plan is staged in eight weeks of milestones, each with an exit gate. The goal of the build is not to ship enterprise-complete software; it's to prove that the loop is believable enough that a litigator wants to come back to it for the second matter.
BenchLab and Infinite Quorum are siblings: BenchLab tests advocacy against judges, Infinite Quorum tests advocacy against juries and general audiences. Different stakes, different rooms, the same idea: that legal advocacy gets better when you can practice it under realistic pressure as many times as you want.