Working title
Catena
An agent-native authority graph of Delaware case law. Westlaw and Lexis were built for human eyes; this one is built for humans and agents as peer first-class users.

Current design direction — the Atlas: doctrine as territory, citations as roads, treatment as road closures, a chain of authority as a route
Explore the interactive demo →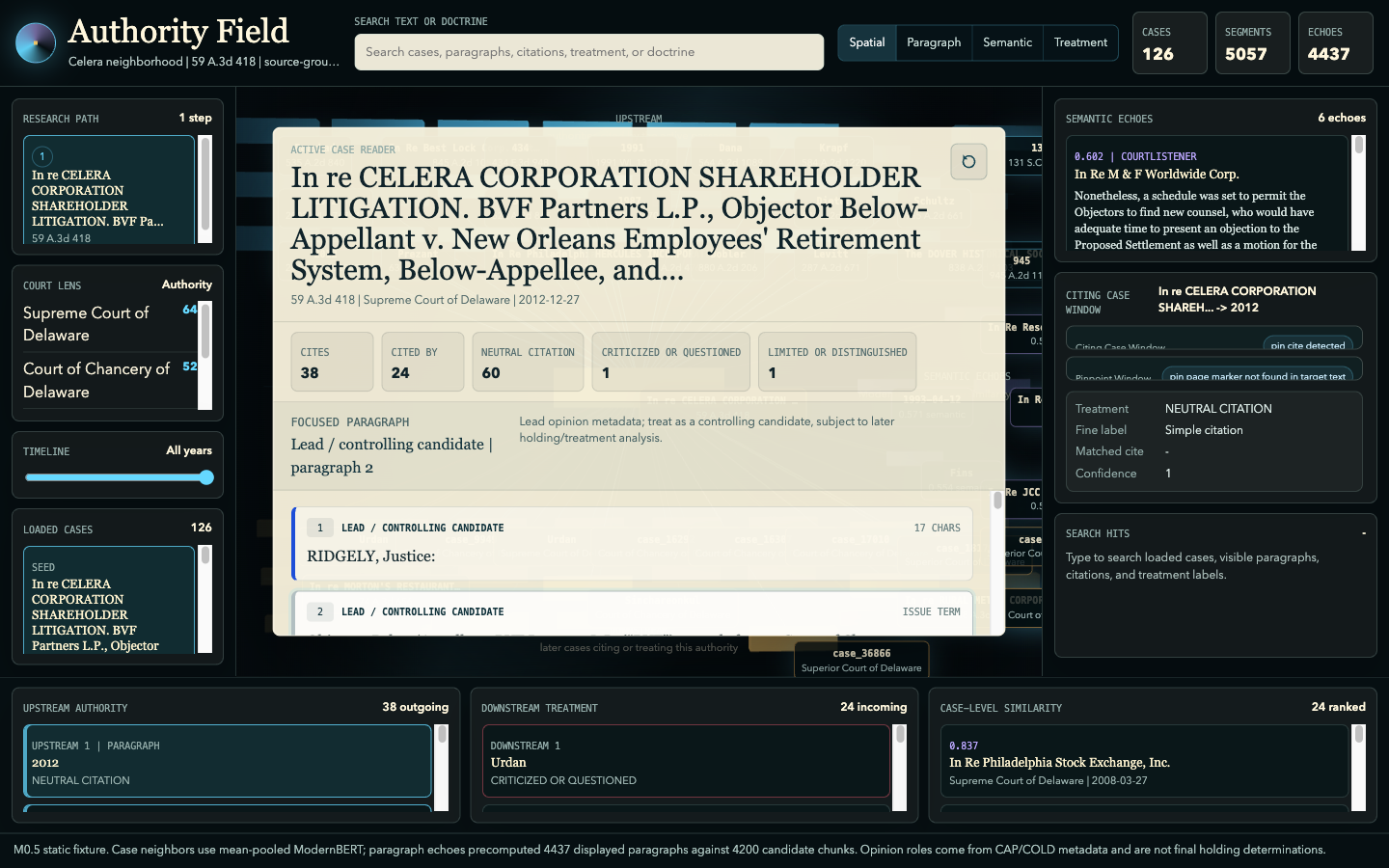
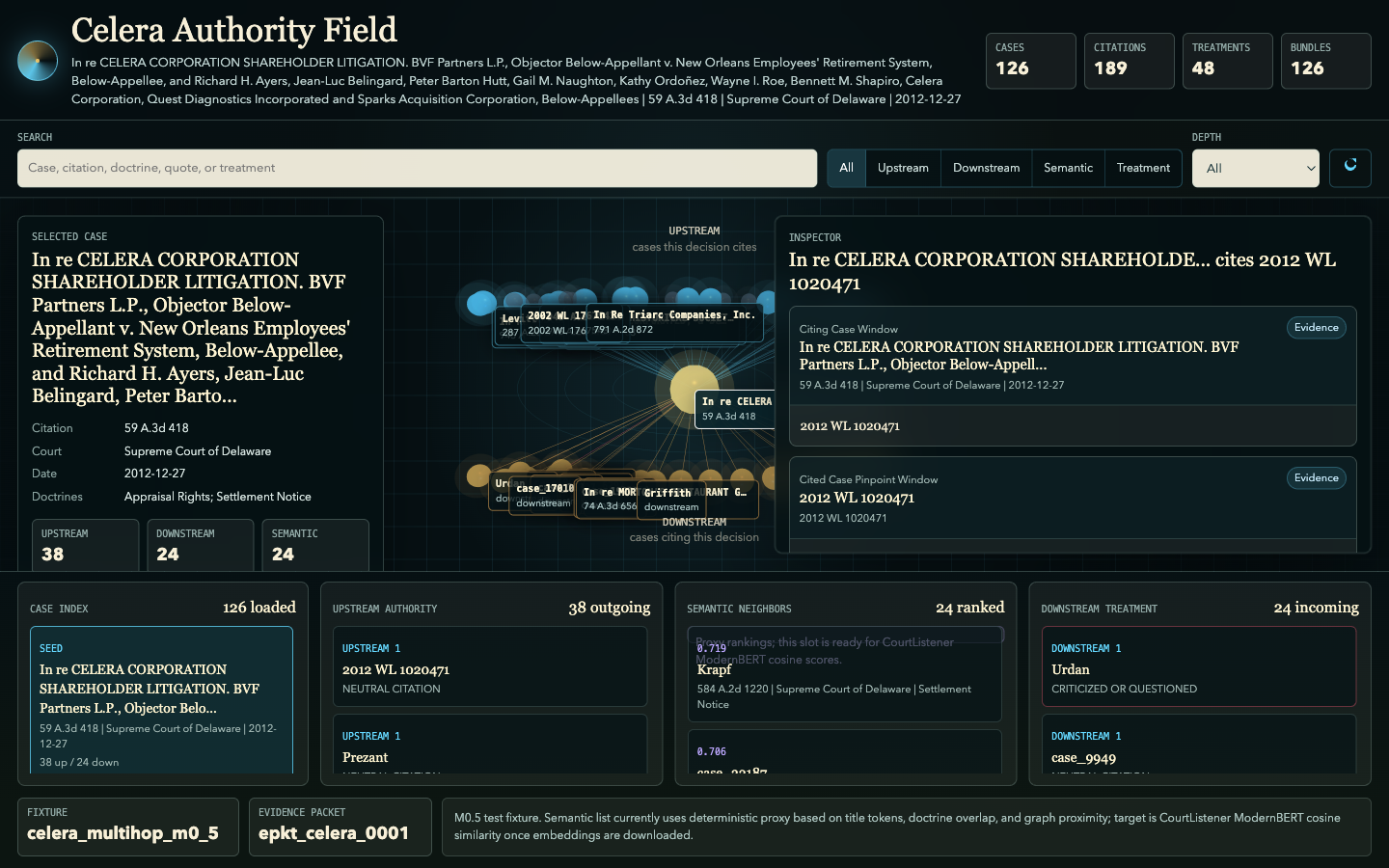
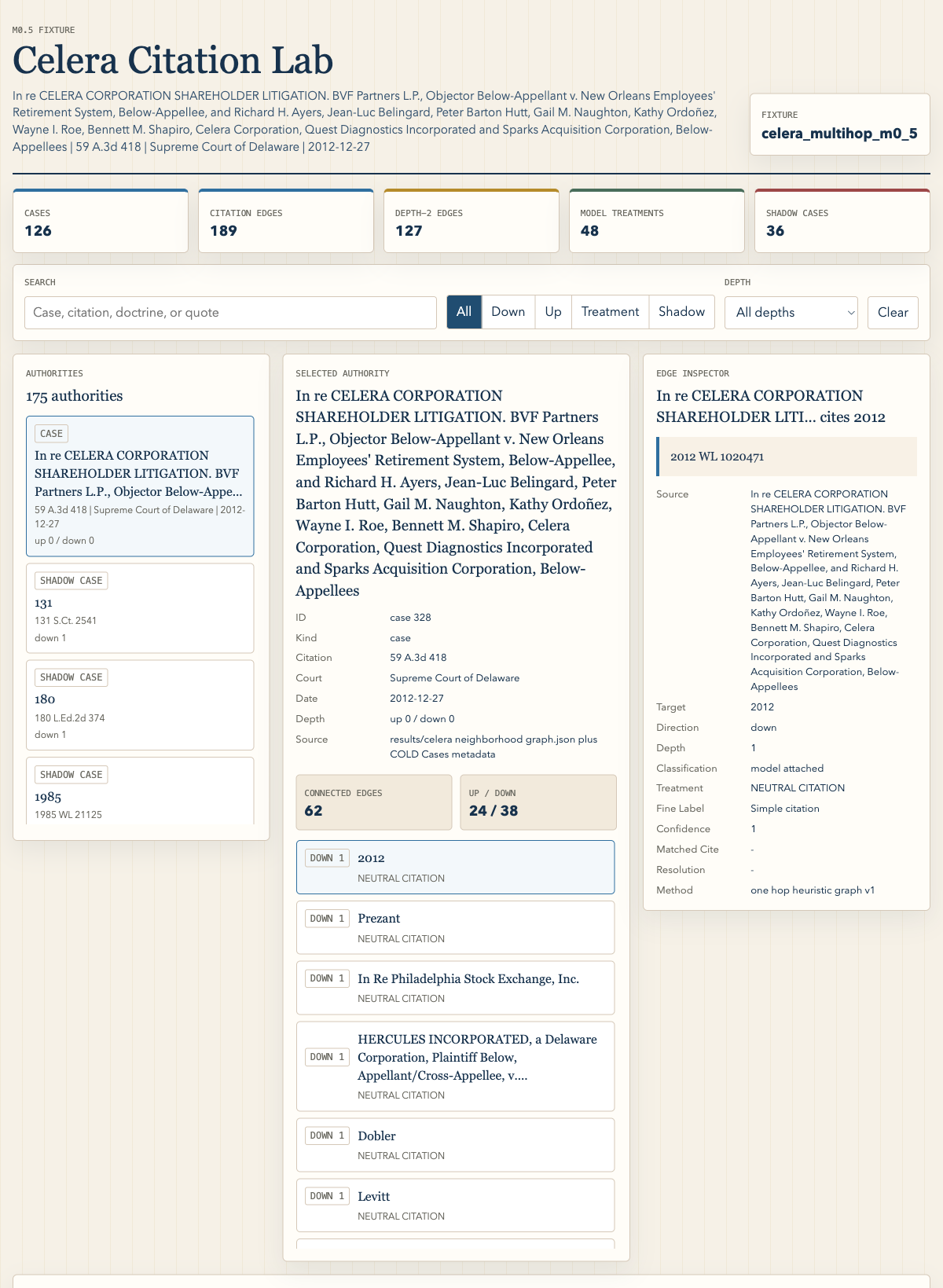
Earlier UI explorations — authority cockpit, authority field, citation lab
The Thesis
Westlaw and Lexis were built decades ago for lawyers running keyword search on a desk computer. Both have been retrofitted for the LLM era — Westlaw AI-Assisted Research, Lexis+ AI, CoCounsel — but the underlying data substrate is still organized around pages of prose and human-readable headnotes. The strategic claim of this project is that there's a real opening for a tool built from the start to serve human and machine consumers of legal authority as peer first-class users — neither retrofitted on top of the other.
Two pieces of evidence anchor that claim.
The first is that hallucination in legal AI looks architectural, not solvable through better retrieval. Stanford's Dahl et al. found that general-purpose LLMs hallucinate on 58–88% of legal queries; Magesh et al. showed that purpose-built legal RAG tools still hallucinate 17–33% of the time, and the dominant failure is misgrounding: a real-looking citation pointing to a real case that doesn't actually stand for the cited proposition. As of April 2026, U.S. courts have sanctioned attorneys in over 1,300 cases for AI-fabricated citations. The architectural answer is to surface authentic source passages from a structured graph rather than generate analytical text. The system shouldn't be able to fabricate, by construction.
The second is that access to justice is structurally aligned with the commercial thesis. Roughly 92% of low-income civil legal problems in the United States receive no legal help. The same architectural commitments that make a tool defensible for a litigation partner — zero content generation, source-anchored atomic operations, an open-data substrate — make it safe to put in front of a pro se litigant who has no lawyer to verify outputs. Same system, two audiences.
The Vision
The product is a structured knowledge graph of Delaware case law. Every decision broken into paragraphs. Every paragraph linked to every other paragraph in the corpus that relates to it. Every link carrying two pieces of information: what kind of relationship it is, and how strong the relationship is.
Direct verbatim quotes become heavy edges. Distantly related concepts become light edges. Citations, treatments (overruling, distinguishing, criticizing), doctrinal applications, factual similarities, statutory constructions, and embedding-based semantic similarities all live in the same graph as different edge types. A human researcher or an autonomous agent can navigate by following links by weight and by type.
"See all of the law" — every paragraph of every Delaware decision, navigable by following the links.
Both faces of the product — the human-facing research interface and the autonomous-agent client — hit the same backend through the same Model Context Protocol server. No parallel stacks. The atomic operation set is small and on purpose: find all cases citing X with treatment Y, trace the evolution of doctrine D over a date range, return the authority cone for this paragraph at weight ≥ 0.3.
The Cartography Turn
The newest research thread started with a question from outside law entirely: how does a mapping service answer continent-scale routing queries in milliseconds? The answer isn't a clever search algorithm — it's that route planners spend enormous offline effort discovering the hierarchy latent in the road network (highways, transit nodes), so each query only touches a small skeleton. Nobody imposed highways on the graph; they're discovered in the data.
Case law has that structure even more explicitly than roads do. Court hierarchy is literal, and landmark cases — Revlon, Unocal, MFW, Aronson — are doctrinal interstates: nearly every long-range path through Delaware fiduciary law runs through a small set of gateway cases. That's precisely the structural property that makes routing preprocessing work, and it's empirically testable on the 39,278 opinions already on disk.
The analogy runs deeper than it first appears. The project's authority-cone query is formally an isochrone — "everything reachable within a cost budget of this point" — a first-class query type in the mapping world. A chain of authority in a brief is a route, and "is there a path of good law from my facts to that favorable holding" is a point-to-point query that hub-labeling techniques answer in microseconds after preprocessing. An overruling is a road closure; recent negative treatment is congestion. Which suggests a behavior no commercial citator offers: rerouting — "your authority chain runs through a case that was just limited; here's the detour through the surviving line."
An agent's context window is its travel budget. Zoom levels — doctrine at Z1, lines of authority at Z2, individual paragraphs at Z3 — are how maps solved the same bandwidth problem decades ago.
Two research tasks are now underway: a survey of the route-planning literature mapped technique-by-technique onto the system's query catalog, and an empirical structural study of the Delaware citation graph testing the doctrinal-highway hypothesis. The same idea reshaped the interface direction: the current design concept renders Delaware law as an engraved atlas — cream paper, navy ink, doctrine as territory, treatment as construction markers — where the same precomputed hierarchy serves the human's zoom slider and the agent's token budget. One structure, two consumers. That symmetry is the whole thesis.
Why Delaware
The proof of concept is scoped tight: Delaware case law, all courts, via the Caselaw Access Project. About 39,278 opinions from 1776 to 2023, currently sitting on my machine as Parquet from Harvard's COLD Cases dataset. Not federal, not multi-state, not the whole country.
Delaware is the right corpus for a first build. It's the practice area I know best as a litigator, which means I can hand-label the gold-set evaluation pairs without outsourcing judgment. The citation density in Delaware Chancery is unusually high. And it's the corpus that matters for the AI legal-tech companies actually building toward this space. Architecture proven on Delaware extends naturally to A2J-canonical jurisdictions (housing, family, immigration, small claims) in a future phase.
Where It Stands
This is a serious research project, not yet a build. The discipline I'm holding myself to is: do the research before the spec; do the spec before the code. Every technical decision has to be traceable to a research output or explicitly noted as a deliberate exception.
What's already settled, from research and synthesis:
Treatment Taxonomy
16/5 hierarchical schema from Demir & Canbaz (2025), derived from Hellyer (2018). Not invented; adopted with reason.
Granularity
Paragraph as the primary unit, with sentence-level offsets where finer granularity helps. Document-level was rejected.
Edge Schema
One treatment edge type plus 19 non-treatment edges. Multi-label is required; ~19% of citing relationships have more than one acceptable label.
Evaluation
Severity-weighted error metric, not standard accuracy. A 40-relationship Delaware gold set is being hand-labeled for the canonical benchmark.
Storage
Postgres primary with Neo4j mirror. Append-only temporal edges with as_of_date so the graph is queryable as of any point in time.
Interface
MCP-primary, thin REST secondary, stateless. Three-tier auth: anonymous A2J, API-key developer, OAuth commercial, all hitting the same server.
What's still pending: the Delaware gold-set annotation pass, the open cartography research thread (route-planning techniques and the citation-graph structural study), and the M1 build itself. A technical spec exists; small fixture-backed interface prototypes are exercising the design commitments before any production code is written.
The Slow Way
This is the project on my desk where I've deliberately slowed down twice. Most of what I build is faster: a weekend prototype, a working app within a month. Catena isn't that. The whole strategic thesis depends on getting the substrate right, and the substrate is a typed knowledge graph with a benchmark and a governance model and an open-data path. That's worth not rushing.
The research-before-spec posture is also a hedge against my own enthusiasm. There's substantial prior art here — Hellyer's taxonomy, Qura's graph architecture (now part of Legora), the LKIF and KeyCite/Shepard's heritage, the CourtListener data model. The fastest way to move past it confidently is to read it first.
The name Catena is a working title. In legal usage, a "catena of cases" is a chain of authority — a sequence of decisions that together support a proposition. It seemed like the right name for a system whose core operation is linking authority to authority by typed weight.